3. Technische specificaties
In deze sectie vind je de technische voorwaarden voor het gebruik van AIOC. Als je niet technisch bent, kun je deze informatie doorgeven aan je IT-afdeling. We leggen uit wat nodig is voor de installatie, zoals netwerkvereisten, accounts en software.
Let op: De systeemvereisten en hardware van de benodigde server verschillen voor trainingsziekenhuizen- en inferentieziekenhuizen.
3.1 Inferentie ziekenhuis
Ziekenhuizen waar het AI-model wordt toegepast, maar waar het model niet wordt getraind noemen we inferentie ziekenhuizen. Deze ziekenhuizen maken dus alleen gebruik van het AI-model, zonder de data te leveren waarmee het model wordt getraind voor doorontwikkeling. Als het model wordt toegepast bij deze ziekenhuizen dan zet het ziekenhuis een dagopnamen dataset klaar op de lokale server van het ziekenhuis en stuurt DHD het model erheen om de resultaten op dezelfde server neer te zetten. Het ziekenhuis zorgt vervolgens voor de upload van de resultaten in het EPD.
Ziekenhuizen die als inferentie ziekenhuis deelnemen aan AI ondersteund coderen dienen lokaal een server in te richten om het model daar te hosten. De vereisten van deze server zijn lichter dan die van de servers van de trainingsziekenhuizen. Maar ook bij inferentie ziekenhuizen waar het AI-model wordt toegepast geldt dat de ongestructureerde data (zoals de ontslagbrieven) binnen de beveiligde IT-omgeving van het ziekenhuis blijven.
3.1.1 Systeemvereisten voor inferentie ziekenhuis
Voor de vantage6 node software, is een server nodig die (bij voorkeur) continue aanstaat. Dit mag ook een virtual machine zijn. De belangrijkste voorwaarden van de inferentieserver zijn:
Ubuntu 22.04 (minimaal)
Docker en Python (versie 3.10) moeten toegankelijk zijn
Toegang tot data
Linux server nodig, geen Windows mogelijk
DHD krijgt vaak de vraag waarom Windows niet geschikt is voor AI ondersteund coderen, dat wordt hier toegelicht. De AI-modellen van AI ondersteund coderen kunnen alleen betrouwbaar draaien op Docker engine wat alleen beschikbaar is op Linux. Windows wordt niet ondersteund, om de volgende redenen:
Geen native Docker Engine: op Windows draait Docker altijd via een virtuele machine (Hyper-V of WSL2). Dit zorgt voor nested virtualisation, wat vaak niet is toegestaan of werkt in ziekenhuisomgevingen.
Veel hogere hardware-eisen: omdat Docker via een VM draait, moet CPU en RAM vooraf vast worden toegewezen. Dit maakt de server aanzienlijk zwaarder en minder efficiënt. Instabiliteit: updates van Windows of Docker Desktop zorgen regelmatig voor verstoringen. In productieomgevingen is dit onacceptabel.
Beperkingen in kernel-functionaliteit: Linux-specifieke functies (cgroups, namespaces, security-profielen) zijn nodig voor networking, security en resourcebeheer. Deze ontbreken op Windows.
Netwerkproblemen: federatieve software zoals vantage6 en multi-container netwerken zijn niet stabiel op Windows.
Automatisering ontbreekt: veel van de DHD installatie en controle processen (systemd-services, cronjobs, scripts, monitoring) zijn gebaseerd op Linux en kunnen niet betrouwbaar draaien op Windows.
Licenties en kosten: Docker Desktop is een betaald product voor organisaties en niet geschikt voor productie. Linux + Docker Engine is gratis en stabiel.
Ondersteuning: DHD biedt alleen support op Linux, omdat alle documentatie, scripts en testen daarop zijn ingericht.
3.1.2 Hardware voor inferentie ziekenhuis
Specificaties voor de hardware voor een inferentieserver zijn als volgt:
≥ 16 cores x86/x64 CPU
≥ 64 GB CPU RAM
≥ 360 GB (SSD)
3.2 Trainingsziekenhuis
Bij trainingsziekenhuizen wordt de data gebruikt om het model te trainen en door te ontwikkelen. Als uw ziekenhuis deelneemt als trainingsziekenhuis, dan zijn zwaardere technische vereisten nodig dan om als inferentie ziekenhuis deel te nemen. Een veel gestelde vraag van IT-afdelingen is of het noodzakelijk is om de server te voorzien van een GPU. Een GPU versnelt het trainingsproces met een factor 100. Voor deelname aan het project als trainingsziekenhuis is het daarom noodzakelijk dat de server wordt opgeleverd voorzien van een GPU. Een uitwerking van de kosten van een GPU is hieronder te zien in Hoofdstuk 3.2.3).
3.2.1 Systeemvereisten voor trainingsziekenhuis
Voor de vantage6 node software, is een server nodig die (bij voorkeur) continue aanstaat. Dit mag ook een virtual machine zijn. De belangrijkste voorwaarden van de trainingsserver zijn:
Ubuntu 22.04 (server of desktop)
Windows is helaas niet mogelijk. Eén van de hardware eisen van de trainingsserver is 1 GPU. Het is binnen Windows niet mogelijk om binnen Docker containers gebruik te maken van deze GPU.
Docker en Python moeten toegankelijk zijn
Toegang tot data
3.2.2 Hardware voor trainingsziekenhuis
Specificaties voor de hardware voor een trainingsserver zijn als volgt:
≥ 16 cores x86/x64 CPU
≥ 64 GB CPU RAM
1 GPU CUDA compatibel NVIDIA kaart
≥ 16 GB GPU RAM
≥ 360 GB (SSD)
3.2.3. Kosten GPU voor trainingsziekenhuis
Binnen het project AI ondersteund coderen is het de wens om zo veel mogelijk ziekenhuizen als trainingsziekenhuis aan te sluiten, zodat we het AI-modellen voor dagopnamen en klinische opnamen kunnen blijven verbeteren. Wanneer een ziekenhuis een trainingsziekenhuis wordt, in plaats van een inferentieziekenhuis zullen er een tweetal wijzigingen doorgevoerd moeten worden:
GPU toevoegen aan de server
Klaarzetten van 5 jaar aan historische data
Hieronder wordt duidelijkheid gegeven over wat het betekent voor ziekenhuizen om een GPU aan te schaffen.
Ten eerste is de setup van de techniek bepalend in wat voor een GPU een ziekenhuis dient aan te schaffen. Je hebt hierin twee smaken:
On-premise = een lokaal (vaste) computer/server aanwezig in het ziekenhuis
Cloud = een niet lokale computer/server, maar online, in de cloud buiten het ziekenhuis
Op dit moment hebben de meeste ziekenhuizen voor project AI ondersteund coderen een on-premise server klaargezet.
3.2.3.1 Prijsbepaling
Ten eerste is het belangrijk om te kijken naar de verschillende soorten GPUs die CUDA compatibel zijn voor NVIDIA GPUs. Hieronder een overzicht van de meest interessante:
GPU |
CPU |
Compute capability |
Azure ($/hour) |
Google ($/hour) |
|---|---|---|---|---|
Tesla K80 |
6 |
3.7 |
0.90 |
0.85 |
Tesla P4 |
8 |
6.1 |
1.00 |
- |
NVIDIA T4 |
16 |
7.5 |
1.20 |
0.75 |
Tabel 1: CUDA compatible NVIDIA Data Center GPUs (bron 1, bron 2)
De NVIDIA T4 kaart is het meest aantrekkelijk en voldoet aan de technische specificaties van het project. Hieronder meer in detail prijsinformatie over deze type GPU.
3.2.3.2 Prijs on-premise
Belangrijk om hierbij aan te geven is dat wij de GPU niet 24/7 nodig hebben. In periodes van trainen verwachten wij de GPU maximaal 16 uur per maand nodig te hebben. Eventueel kan de GPU dus gedeeld worden met andere lokale servers in het ziekenhuis.
De eenmalige aanschafkosten van NVIDIA T4 videokaart voor een on-premise server zijn ongeveer €3.000,-.
Mochten jullie in het ziekenhuis een andere videokaarten beschikbaar hebben, neem dan contact met ons op of we ook met dit type kunnen werken.
3.2.3.3 Prijs per type cloud aanbieder
Belangrijk om hierbij aan te geven is dat wij de GPU niet 24/7 nodig hebben. In periodes van trainen verwachten wij de GPU maximaal 16 uur per maand nodig te hebben. Onderstaande prijzen zijn uitgegaan van 16 uur.
Per type cloud:
Google Cloud (bron: n1-highmem-16):
16 uur per maand = €17,84 per maand
Azure Cloud (bron: NC16as T4 v3)
16 uur per maand = €22,30 per maand
3.3 Specificaties software (voor trainings- en inferentie ziekenhuizen)
Specificaties voor de software zijn als volgt:
Docker (we gebruiken docker engine, docker desktop is niet mogelijk)
Hier een Link naar installatie Docker Engine op een Ubuntu server.
Python == 3.10 (we gebruiken de venv versie)
Vantage6 (zie hoofdstuk 3.7 voor installatie uitleg)
3.3.1 Testen of Docker werkt
Graag willen wij u vragen om na de installatie van Docker te controleren of Docker werkt. Dit kunt u als volgt doen. Type in Command Prompt:
docker run hello-world
of
docker ps
3.3.2 Testen of Python werkt
Graag willen wij u vragen om na de installatie van Python te controleren of Python werkt en of de juiste versie (3.10-venv versie) is gedownload. Dit kunt u als volgt doen. Type in Command Prompt:
python3 --version
3.4 Netwerk (zowel voor trainings- als inferentie ziekenhuizen)
Specificaties voor het netwerk zijn als volgt:
≥ 100Mbit ethernet
Port 443/TCP (https) open voor uitgaand verkeer naar de volgende zes urls:
Microsoft:
https://login.microsoftonline.com
DHD Docker registry:
https://drplugindhdprd.azurecr.io
https://drplugindhdprd.westeurope.data.azurecr.io
DHD Blob storage:
https://stplugindhdp.blob.core.windows.net
DHD Vantage6 server:
https://plugin.dhd.nl
3.5 Accounts (zowel voor trainings- als inferentie ziekenhuizen)
Om het AI-model te kunnen toepassen hebben DHD medewerkers toegang nodig tot de lokale server die ingericht wordt bij het ziekenhuis. Dit moet een beveiligde verbinding zijn, bij voorkeur met een persoonlijk inlogaccount op de ziekenhuisomgeving/jump server een DHD-account op de Linux-server.
Persoonlijke accounts tot ziekenhuisomgeving/jump server:
Indien aanwezig verwacht DHD dat de eerste loginstap, zoals die via VPN, intranet, en andere systemen, uitgevoerd wordt met persoonlijke accounts vanuit informatiebeveiligings oogpunt.
Het account voor de Linux server mag wel gedeeld zijn, het gaat echt alleen om de toegang tot de ziekenhuisomgeving.
Voor het opvragen welke personen van DHD een persoonlijke account nodig hebben, kunt u een mail sturen naar ai-coderen@dhd.nl.
DHD-account voor Linux server:
Dit mag een gedeeld DHD account zijn.
Het is belangrijk dat dit account aan de Docker Group wordt toegevoegd. Voor meer informatie: Add user to Docker group
Het is belangrijk dat deze accounts “lees” en “schrijf” toegang hebben tot de map waar de data wordt geplaatst.
3.6 Folderstructuur server
Net zoals het bij het datamodel is het belangrijk dat er een eenduidige folderstructuur aangehouden wordt op de geïnstalleerde server voor de werking van het model. In de configuratie wordt per ziekenhuis aangegeven waar het model naar de data moet zoeken. De data folder zelf hoeft dus niet op een bepaalde standaard plek op de server klaargezet te worden. Echter, binnen de data folder houden wij een standaard structuur aan. De folderstructuur die binnen de datafolder wordt verwacht wordt hieronder beschreven en getoond.
Hier kan je informatie vinden over welke folder structuur het model verwacht en waar je de resultaten op kunt halen.
3.6.1 Lokale data management overzicht
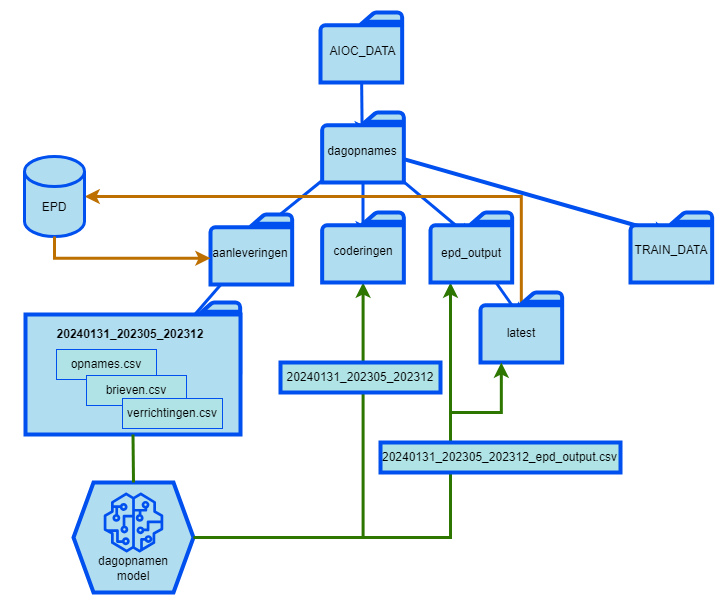
De bestanden aangeleverd door het ziekenhuis komen binnen in een map aanleveringen per aanlevering. De resultaten van het model kunnen vanuit de map epd_output opgehaald worden en ingelezen worden in het EPD.
3.6.2 Folders
AIOC_DATA
De hoofdmap voor alle data m.b.t. het project AI ondersteund coderen. Hierin zal een submap komen voor dagopnames en klinische opnamen.
dagopnames
De hoofdmap voor alle dagopnames data. Hierin worden de aanleveringen, coderingen en epd_output mappen aangemaakt.
aanleveringen
In deze map (/.../AIOC_data/dagopnames/aanleveringen/) levert het ziekenhuis de aanleverfolders aan. Elke folder dient behouden te blijven om aanleveringen te kunnen vergelijken en als back-up te fungeren.
Belangrijk! De naamgeving van de aanleverfolders moet volgens deze naamconventie: exportdatum_startjaarmaand_eindjaarmaand.
Hierbij is de exportdatum de datum dat de export is gemaakt of klaargezet, bijvoorbeeld 20240402.
Met startjaarmaand en eindjaarmaand bedoelen we de periode van de opnames die gecodeerd dienen te worden, bijvoorbeeld voor kwartaal 2 is dat: 202404_202406
Deze naamconventie geeft inzicht in het moment van klaarzetten van het exportbestand en de periode van de aangeleverde dagopnames. Hierdoor houden we een goed onderscheid en overzicht van de verschillende aanleveringen. Indien slechts een deel van een maand wordt aangeleverd, dan moet de gehele maand toch in de naamgeving worden opgenomen. Bijvoorbeeld, voor een gedeeltelijke aanlevering binnen de maand januari t/m maart 2024, klaargezet op 2 april, dan wordt de naamgeving van de aanleverfolder 20240402_202401_202403. In deze folder verwachten we de verschillende csv’s, zie Hoofdstuk 3.6.3 hieronder.
coderingen
In deze map maakt de AIOC applicatie een werkmap aan waar onder andere een kopie van de aangeleverde data, checkpoint bestanden en resultaten komen te staan. Dit is vooral een werkmap voor de data scientisten.
epd_output
In deze map worden de uiteindelijke resultaten/output bestanden klaargezet. Deze bestanden kunnen direct in het EPD geïmporteerd worden.
latest
In deze map wordt het laatste outputbestand van de AIOC applicatie geplaatst. Het bestand in deze map kan gebruikt worden om de resultaten te importeren in het EPD.
TRAIN_DATA (alleen voor trainingsziekenhuizen)
In deze map worden de trainingsdata opgeslagen. Deze map is alleen voor trainingsziekenhuizen en bevat data van meerdere jaren met ICD-10 codering om het model te trainen.
3.6.3 Aanleverbestanden vereisten
In de aanleverfolder zitten 3 verschillende bestanden:
opnames
verrichtingen
brieven (kan samengevoegd of los per document type aangeleverd worden)
Belangrijk! Voor het goed inlezen van de bestanden zijn de volgende zaken van belang:
De namen van deze bestanden zijn als volgt: opnames.csv, verrichtingen.csv en brieven.csv/documenten.csv/verslagen.csv (of als ze los worden aangeleverd: poli.csv, pa.csv, ontslag.csv, ok.csv en scopie.csv)
De bestanden dienen als csv aangeboden te worden met een UTF-8 encoding
Als delimiter moet ofwel een komma (
,) of een semikomma (;) worden gebruikt
3.7 Installatie vantage6
In dit hoofdstuk wordt stap-voor-stap beschreven hoe het ziekenhuis zelf vantage6 kan installeren op de lokale ingerichte server. Een aantal stappen zal door DHD gedaan worden, dit is aangegeven in de titel van de stap.
3.7.1 Randvoorwaarden (door ziekenhuis zelf)
Docker geïnstalleerd (zie Hoofdstuk 3.3)
Huidige gebruiker heeft voldoende rechten om Docker te gebruiken (Let op! Bij een Linux server is het belangrijk dat het DHD-account wordt toegevoegd aan de Docker usergroup)
Python == 3.10 (eventueel kan Pyenv als Python manager gebruikt worden)
Tip
Voor de installatie van Python packages raden we een virtual environment aan. Zie de documentatie van de gebruikte Python distributie voor meer informaite over hoe dit op te zetten.
Distributie |
Documentatie |
|---|---|
Python3 (vanilla) |
|
Anaconda |
3.7.2 Installatie van vantage6 software (door ziekenhuis zelf)
Vantage6 nodes draaien als Docker container op de server. Om interactie met deze containers te vergemakkelijken, is er een command line interface (CLI) beschikbaar. Deze CLI is geschreven in Python3 en is als package beschikbaar via PyPI.
Het volgende commando installeert de laatste versie van CLI:
pip install --upgrade vantage6
Tip
Het volgende commando verifieert of installatie van de software succesvol was.
vnode --help
3.7.3 Configuratie van de node(s) (door DHD)
Binnen een vantage6 netwerk is het mogelijk om verschillende samenwerkingsverbanden te definieren. Per samenwerkingsverband wordt bepaald 1) welke data wordt gebruikt, en 2) wat er precies mee gedaan mag worden.
Per samenwerkingsverband, wordt een node geconfigureerd: de node heeft toegang tot de (juiste) data én houdt in de gaten dat alleen de toegestane algoritmes op de data worden toegepast.
Om een configuratiebestand voor een nieuwe node aan te maken wordt vanaf de command line het commando vnode new gebruikt.
vnode new
Dit start een “wizard” die een aantal vragen stelt. Deze worden hieronder nader toegelicht.
Prompt |
Antwoord / Omschrijving |
|---|---|
Please enter a configuration-name |
Naam van de node (en het configuratiebestand).
|
Please select the environment you want to configure |
Kies |
Enter given api-key |
De API-key wordt gebruikt voor authenticatie van de node bij de server. Deze ontvangt u van DHD. |
The base-URL of the server |
Kies voor AIOC: https://plugin.dhd.nl |
Enter port to which the server listens |
Kies/typ |
Path of the api |
Haal de standaardwaarde |
Task directory path |
Accepteer de voorgesteld waarde. |
Task directory path |
Accepteer de voorgesteld waarde. |
Do you want to add a database? |
Kies |
Enter unique label for the database |
Accepteer de voorgestelde waarde |
Database URI |
Voer de URI voor de database in. Dit is of een URI in de vorm |
Database type |
Kies het juiste database/bestands type. |
Do you want to add a database? |
Kies |
Which level of logging would you like? |
Kies |
Do you want to connect to a VPN server? |
Kies |
Subnet of the VPN server you want to connect to |
Kies voor AIOC: |
Enable encryption? |
Kies |
Path to private key file |
Geef een absoluut pad op naar de private key. Deze key maken we in de vervolgstap Aanmaken private key aan. |
Na afronding van de wizard, wordt de locatie van het aangemaakte configuratiebestand op het scherm getoond. Dit bestand kan m.b.v. een tekst-editor (bijv. Notepad of Visual Studio Code) worden geopend en aangepast.
De locatie van dit configuratiebestand kan ook worden teruggevonden met behulp van het volgende commando:
vnode files
3.7.4 Aanmaken private key (door DHD)
Het handmatig aanmaken van een private key kan via het volgende commando:
vnode create-private-key
Hiervoor heeft zijn de gebruikersnaam en password, verstrekt door DHD, IKNL, of EZA, noodzakelijk.
3.7.5 Starten en stoppen van een node (door DHD)
Om een node te starten, wordt het volgende commando gebruikt:
vnode start
Om een idee te krijgen van wat er op de achtergrond gebeurt, is het mogelijk om de output van de node naar het scherm te sturen. Dit kan op twee manieren:
vnode start --attach
Of op een later moment via het commando:
vnode attach
Voor het stoppen van een node bestaat een vergelijkbaar commando:
vnode stop
3.7.6 Meer informatie
Zie voor meer informatie de documentatie van vantage6
Let op: de specificaties in de officiële vantage6 documentatie kunnen afwijken van de specificaties in dit document.